Abstract
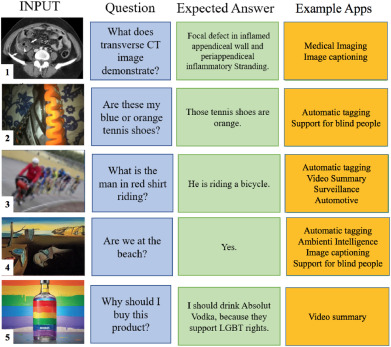
Visual Question Answering (VQA) is an extremely stimulating and challenging research area where Computer Vision (CV) and Natural Language Processig (NLP) have recently met. In image captioning and video summarization, the semantic information is completely contained in still images or video dynamics, and it has only to be mined and expressed in a human-consistent way. Differently from this, in VQA semantic information in the same media must be compared with the semantics implied by a question expressed in natural language, doubling the artificial intelligence-related effort. Some recent surveys about VQA approaches have focused on methods underlying either the image-related processing or the verbal-related one, or on the way to consistently fuse the conveyed information. Possible applications are only suggested, and, in fact, most cited works rely on general-purpose datasets that are used to assess the building blocks of a VQA system. This paper rather considers the proposals that focus on real-world applications, possibly using as benchmarks suitable data bound to the application domain. The paper also reports about some recent challenges in VQA research.