Abstract
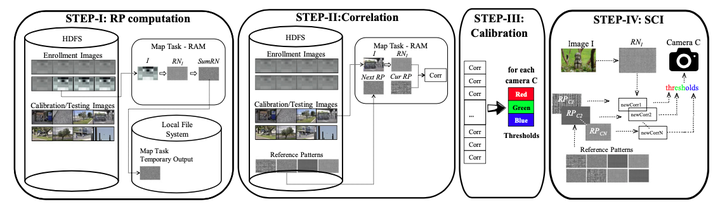
Hadoop is a software framework allowing for the possibility of coding distributed applications starting from a MapReduce algorithm with very low programming efforts. However, the performance of the implementations resulting from such a straightforward approach are often disappointing. This may happen because a vanilla implementation of a MapReduce distributed algorithm often suffers of some performance bottlenecks that may compromise the potential of a distributed system. As a consequence of this, the execution times of the considered algorithm are not up to the expectations. In this paper, we present the work we have done for efficiently engineering, on Apache Hadoop, a reference algorithm for the Source Camera Identification problem (i.e., determining the particular digital camera used for taking a given image). The algorithm we have chosen is the algorithm by Lukáš et al. A first implementation has been obtained in a small amount of time using the default facilities available with Hadoop. However, its performance, analyzed using a cluster of 33 PCs, was very unsatisfactory. A careful profiling of this code revealed some serious performance issues targeting the initial steps of the algorithm and resulting in a bad usage of the cluster resources. Several theoretical and practical optimizations were then tried, and their effects were measured by accurate experimentations. This allowed for the development of alternative implementations that, while leaving unaltered the original algorithm, were able to better use the underlying cluster resources as well as of the Hadoop framework, thus allowing for much better performance and reduced energy requirements than the original vanilla implementation.